In January 2025, a few weeks before Monad's testnet launch, our test suite started failing. The cause was a new feature that was essential for a high-performance network: support for undecided blocks. This is the ability to execute blocks optimistically ahead of finality and abandon them if a competing block is finalized instead (a “reorg”). This feature broke our key-value cache for accounts and storage. The cache, which had long been a cornerstone of our execution performance, was now returning incorrect data. Values written by block proposals that were later abandoned were leaking into subsequent executions, producing wrong results.
The immediate fix was straightforward: disable the cache. The performance cost was stark. Transaction execution throughput dropped by half. We could have launched without the cache and added it back later, but we didn't want to accept the performance hit. The race was on to design a correct and performant caching solution.
Monad pipelines consensus and execution to achieve high throughput, meaning proposed blocks are executed before consensus finality. The cache can now contain data from blocks that never become part of the final chain, and a conventional cache has no way to distinguish good data from poisoned data.
We couldn't avoid undecided blocks. They are an artifact of pipelined consensus, a core driver of Monad’s performance. And we didn’t want to give up key-value caching. It accounted for half our throughput. We needed a new design that could deliver the speed of caching while correctly handling the uncertainty of undecided blocks. What follows is the two-tier key-value caching architecture we built to solve this problem.
Background: Trie Storage and Key-Value Caching
Monad stores its full blockchain state data, which includes accounts and contract storage, in a trie. A trie is a tree-like data structure where values are reached by traversing a path of nodes determined by the key. For accounts, the key is a 20-byte address and the value includes the account’s balance, code hash, and nonce. For contract storage, the key combines a 20-byte contract address with a 32-byte storage key, mapping to a 32-byte value.
The problem with tries is that lookups are inherently sequential. To read a single value, the system must traverse the trie from root to leaf, fetching each node to determine the next step. When nodes reside on disk, each step in the traversal can incur a disk read. As the blockchain state grows and the trie deepens, these lookups get slower (100s of microseconds).
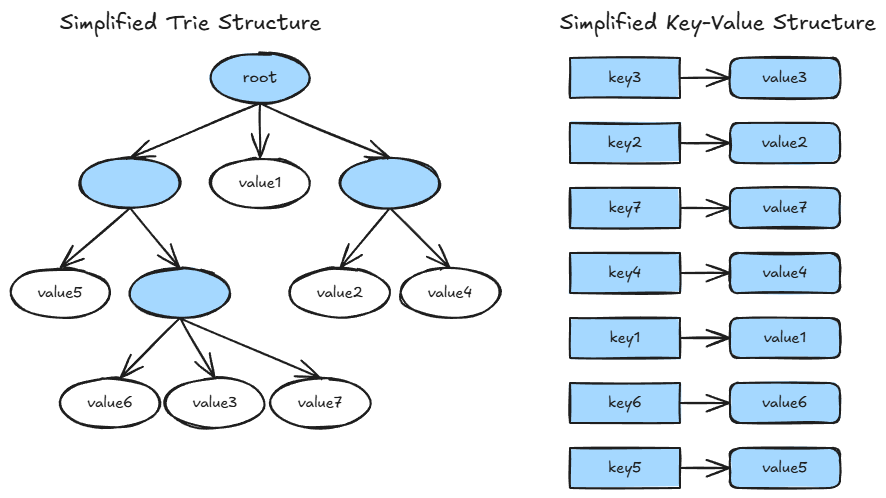
The key-value cache bypasses this entirely. It maintains a direct mapping from keys to their most recent values in memory. A cache hit returns the value immediately (100s of nanoseconds), skipping the trie traversal altogether. The performance difference is dramatic (~1000x), which is why disabling the key-value cache cost us half our transaction execution throughput.
But to understand why undecided blocks broke this cache, we first need to understand the block lifecycle in Monad's pipelined architecture, where execution runs ahead of finality.
When Blocks Are Undecided
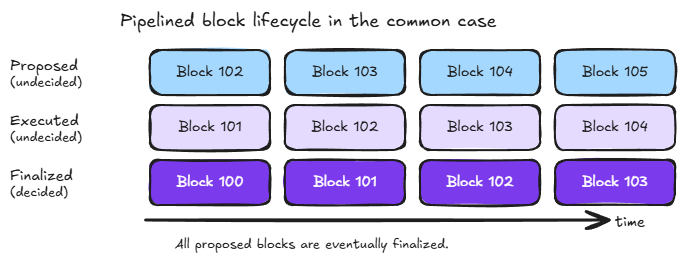
Every proposed block begins as undecided. When a block is proposed, its transactions are executed optimistically and the resulting state changes recorded. However, those changes are not persistent until consensus finalization, at which point the block is no longer considered undecided.
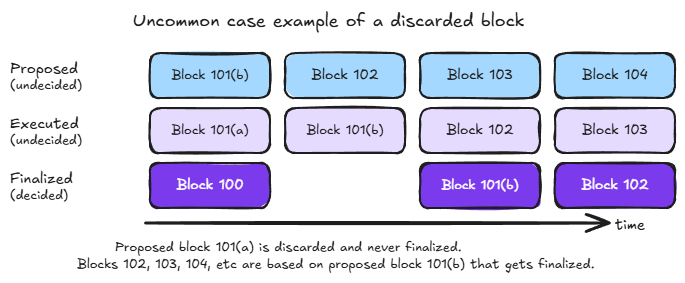
Most blocks are finalized, meaning their state changes become permanent and irreversible. But the cache must handle the possibility of discarded blocks correctly. The following diagrams show examples of both cases: the common case where all proposed blocks are eventually finalized and the rare case where a competing block is proposed and finalized while the original is discarded.
Why Undecided Blocks Complicate Key-Value Caching
Consider the following scenario:
- Block 101(a) is proposed and executed. The cache now contains values written by 101(a).
- Block 102(a), building on 101(a), is also proposed and executed. More values enter the cache.
- A competing block 101(b) is proposed, executed, and finalized. Block 101(a) is discarded, and with it, 102(a) is also invalidated.
- The cache now contains values from blocks that are not part of the finalized chain. Any subsequent execution that reads these values will produce incorrect results.
A conventional key-value cache has no way to distinguish between values written by finalized blocks and values written by discarded ones. It simply maps keys to their most recent values. Once a discarded block's writes enter the cache, they silently poison future lookups. This is exactly the bug we hit before testnet.
One approach would be to keep a conventional cache and invalidate it entirely whenever a competing block needs to be executed. In our example, the cache would be flushed before executing 101(b), regardless of whether 101(b) or 101(a) ultimately wins. This means the cache is invalidated more often than blocks are actually discarded, any time competing proposals appear, not just when one loses. And competing proposals tend to occur precisely when the network is under stress, which is the worst time to lose the cache. We needed a design that could handle competing blocks surgically, without disrupting the cache as a whole.
A Two-Tier Design
To accommodate undecided blocks efficiently, the Monad key-value caches for accounts and storage use a novel two-tier design:
- The first tier is the undecided tier, holding separate states for each undecided block to facilitate discarding the state of discarded blocks.
- The second tier is the finalized tier composed of conventional caches, one for accounts and one for storage, containing values consistent with the latest finalized block. The vast majority of cached items are in this tier.
A key insight is separating data by certainty. The undecided tier keeps speculative state isolated per block, so discarding a block means simply dropping its entry. The finalized tier holds only data that will not need to be reverted. Let's look at each tier in detail.
The Undecided Tier
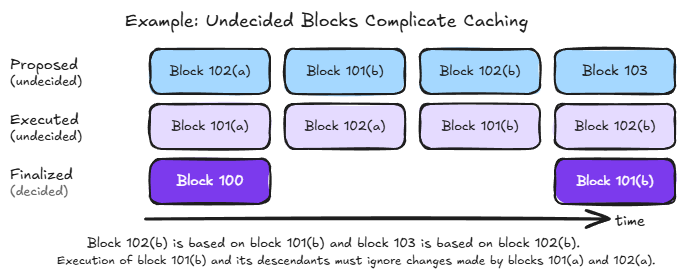
Each undecided block builds on a specific parent, either the latest finalized block or another undecided block. When multiple blocks compete for the same position in the chain, as with 101(a) and 101(b) in our example, they branch into separate paths. The result is a tree of undecided blocks descending from the latest finalized block. The following diagram shows this structure at the start of executing block 103 in the previous example.
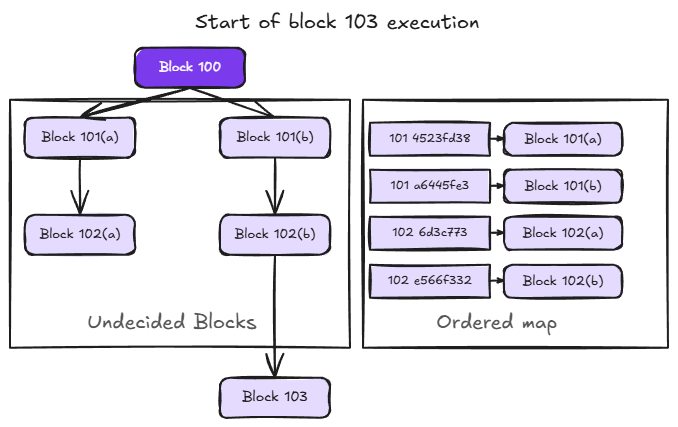
The main data structure in the undecided tier is an ordered map keyed by the concatenation of block number and block id, mapping to the state of the corresponding block. In the example above, the map contains entries for blocks 101(a), 101(b), 102(a), and 102(b). The block number comes first in the key so that all blocks at the same height are grouped together. This is what allows efficient cleanup when a block is finalized, as we'll see shortly. Within the same height, the ordering between entries (e.g., 101(a) vs 101(b)) is determined by the block id, which is a hash unrelated to chronological order. The tree structure is conceptual. To walk back through a block's ancestors, we look up each block's parent in the map.
Block Transitions
The undecided tier must be updated as blocks are executed and finalized. These are the two key operations.
Block Execution
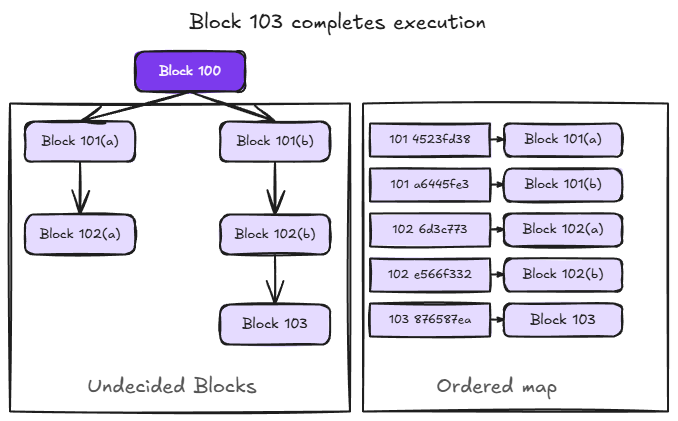
When a block completes execution, its state, including the key-value items it read and wrote, is inserted into the ordered map. For example, when block 103 completes execution, its state is added to the map as shown below.
Block Finalization
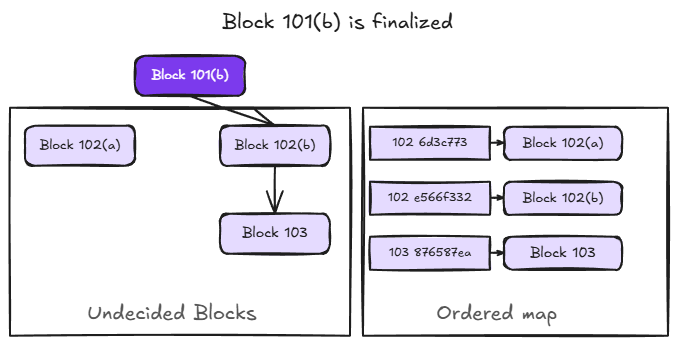
When a block is finalized, two things happen: the finalized block's state is removed from the ordered map and its key-value items are promoted to the finalized tier; and all other undecided blocks at the same block number are discarded, since the finalized block has won.
In our example, when block 101(b) is finalized, block 101(a) is discarded and block 101(b)'s cached items move to the finalized tier. Block 102(a) is also effectively invalid at this point as it was built on 101(a), which is no longer part of the chain. For efficiency, however, 102(a) is left in the ordered map rather than removed immediately. It will be cleaned up when block 102 is finalized, avoiding the need to scan the map for descendants of discarded blocks.
The Finalized Tier
The finalized tier holds data that will not need to be reverted. It is implemented as two conventional LRU (least recently used) caches, one for accounts and one for storage, containing values consistent with the latest finalized block. The vast majority of cached items live in this tier.
An LRU cache supports expected constant-time lookups and insertions. When the cache reaches capacity, it evicts the least recently used item to make room, keeping frequently accessed data available. Because this tier only contains finalized data, there is no risk of poisoned values. The complexity of undecided blocks is handled entirely by the tier above.
A subtle but important property of this design: the finalized tier may contain stale values, specifically values that are consistent with the latest finalized block but have since been overwritten by undecided ancestors of the currently executing block. This is safe because the lookup always consults the undecided tier first, walking back through the current block's ancestors. If any ancestor modified a value, the lookup will find it there and never reach the stale value in the finalized tier. The finalized tier is only consulted for keys that no undecided ancestor has touched, in which case the finalized value is guaranteed to be correct. This property is what makes the novel two-tier design work. The undecided tier completely covers any inconsistencies with the finalized tier, without requiring the finalized tier to be updated or invalidated as undecided blocks are executed or discarded.
Key-Value Cache Lookup
To tie it all together, let's trace a lookup during the execution of block 103. The latest finalized block is 100, and block 103's undecided ancestors are 102(b) and 101(b). The lookup proceeds through these layers until the value is found:
- Current transaction state. The item may have already been accessed by the current transaction.
- Current block state. Another transaction in block 103 may have already accessed it.
- Undecided ancestors. We walk back through 103's ancestry in the ordered map, first 102(b), then 101(b), checking each block's state. This is where the tree-to-map design pays off: we look up each ancestor directly by its block number and id.
- Finalized tier. If none of the undecided ancestors touched this key, we look it up in the LRU cache, which holds values consistent with block 100.
- Trie. If the item is not in any cache, we fall back to reading it from the full trie.
At each layer, a hit returns immediately. The first value found is guaranteed to be the most recent correct value for the current execution context. This is the property that makes the two-tier design safe: the undecided ancestors always mask any stale data in the finalized tier.
Conclusion
The two-tier key-value cache both preserves Monad’s performance characteristics and robustly handles undecided blocks. We shipped monad PR#1138 in time for testnet launch, and the two-tier cache continues to be used in mainnet. By separating cached data by certainty, isolating undecided block states in the first tier and keeping only finalized data in the second, we preserved the performance of key-value caching without sacrificing correctness in Monad's pipelined architecture, where blocks are executed optimistically.
What began as a crisis before testnet led to a design that is both robust and efficient. Discarding a block means dropping a single entry from the ordered map. No cache flushes, no rebuilding from disk, no throughput disruption at the worst possible moment.
There is more to explore. The performance benefits of key-value caching across multiple blocks could be incorporated into the pricing model to further increase the network's throughput safely. While the possibility of competing blocks is very low currently, the two-tier cache provides robustness and could be leveraged in future changes to the consensus algorithm.
