Category Labs is excited to announce our updated MonadBFT research paper, which substantially revises and extends our previous work. Building on our original MonadBFT protocol, which provided tail-forking resistance through reproposals, the updated protocol introduces fast recovery mechanisms that eliminate the need for reproposals in the most common failure settings and isolate the effects of a Byzantine leader to a single round. The result is a 2x reduction in failure recovery time while maintaining all security guarantees. This newly optimized MonadBFT protocol has been running on testnet and will be running on Monad mainnet from Day 1.
Quick Recap: The Tail-Forking Problem
In our previous blog post, we demonstrated how pipelined BFT protocols are vulnerable to tail-forking. Consider an example where Valerie, Will, and Xander lead three consecutive rounds. In standard pipelined consensus, Valerie's block cannot be finalized if Will (the subsequent leader) goes offline—this is because pipelined protocols rely on the next leader to collect votes for the previous leader's proposal. With Will offline and the votes lost, Xander ends up abandoning Valerie's block. The situation is even worse if Will is malicious rather than offline: he can intentionally abandon Valerie's block to steal her transactions and extract MEV for himself. That’s why pipelined consensus protocols should be tail-forking resistant: once a QC for a block is formed, it should not be abandoned (except in the rare case of leader equivocation).
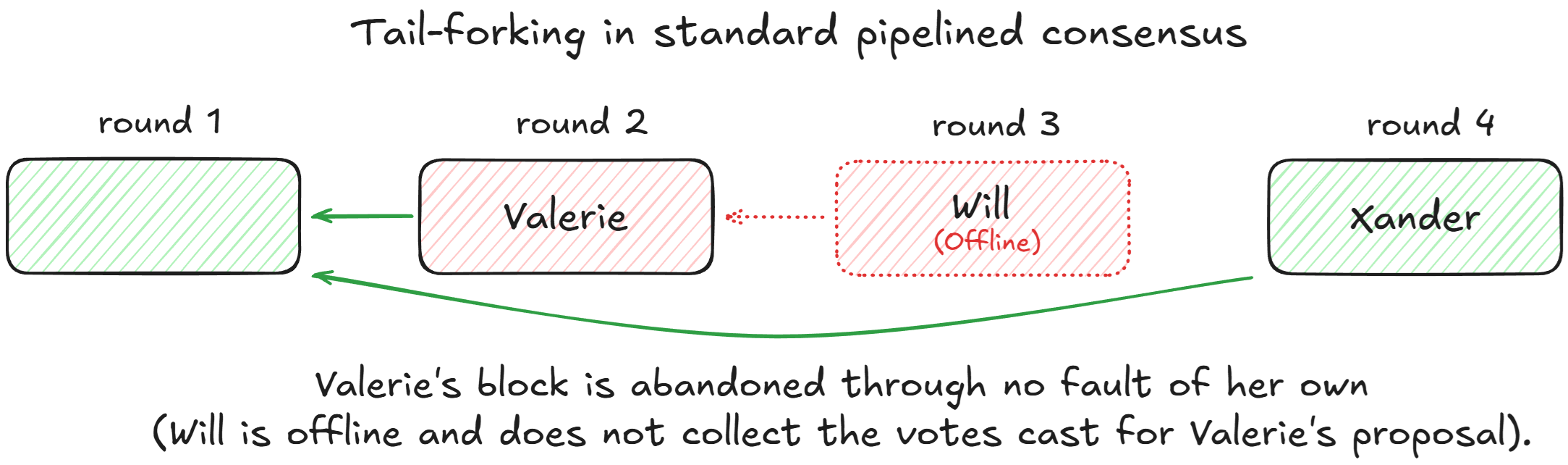
The original MonadBFT design, which we published earlier this year, achieved tail-forking resistance through reproposals. When sending timeout messages, validators include their tip—in most cases, this is simply the header of the most recent proposal that they voted for. The next leader identifies the "high tip" (most recently proposed) among all received timeout messages and must repropose it or provide proof that this proposal couldn't have received a QC. This requirement is what provides tail-forking resistance, ensuring that blocks with sufficient honest support ($f+1$ honest votes) don't get abandoned.

This ensured that honest validators' blocks would eventually be included. However, it came with a cost. The reproposal itself consumes an entire round, and during that round, no new block can be proposed. If a user submitted a transaction during Will’s round, they would have to wait two additional rounds before any possibility of their transaction being proposed. The new MonadBFT paper shows we can maintain tail-forking resistance and avoid a round dedicated to reproposal in most cases. If the next leader (Xander) has a QC for Valerie’s block and can provide evidence that Will did not make a valid proposal with sufficient support, then Xander can make a fresh block proposal that directly extends Valerie’s block. How is that achieved? Via fast recovery.
Fast Recovery Example
We now illustrate how fast recovery works in our optimized MonadBFT protocol.
In traditional HotStuff pipelined consensus, only the next leader collects votes. If the next leader is offline, the votes are lost. The first mechanism for fast recovery is for validators to send their vote not only to the next leader, but also to the current (online) leader. We call this additional vote a backup vote, from which the current leader forms and broadcasts a backup QC.
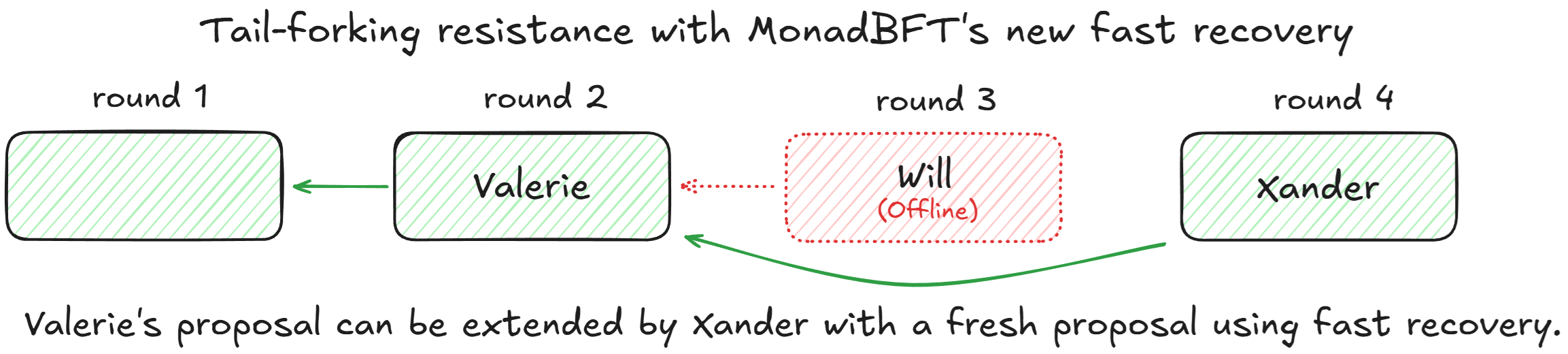
Let’s go back to our earlier example with Valerie, Will, and Xander. This time we’ll use fast recovery:
- Valerie proposes in round 2 to all the other validators
- Each validator validates the block and submits a vote to the next leader (offline Will) and a backup vote to the current leader (online Valerie)
- Valerie collects $2f+1$ votes and forms a QC herself
- Valerie broadcasts it as a backup QC to all validators
- Round 3 times out because Will is offline
- All validators submit timeout messages to the next leader Xander with the backup QC instead of their tip (explained below)
- Xander directly extends Valerie’s proposal with his own fresh block in round 4
Fast recovery is instant (no reproposal) after a timeout is detected, and a single faulty leader causes only a single round to fail! Let’s examine these two properties in more detail.
Property #1: Fast Recovery Without Reproposal
When Xander becomes leader after Will's timeout, he receives timeout messages from validators. These timeout messages will include the QC instead of a tip per another modification in the updated MonadBFT protocol.
In our example, Valerie successfully built and disseminated her backup QC, and Will did not make a proposal. Hence, validators report Valerie’s QC in their timeout messages. Xander can conclude from the lack of tips in timeout messages that Will either did not make a proposal or it did not achieve sufficient support. In either case, no QC could have formed for Will’s proposal, making it safe to abandon.
Consequently, Xander can directly extend Valerie's proposal with his own fresh block. Recall the no-tail-forking requirement—Valerie's proposal must not be abandoned. However, instead of spending a round on reproposal, Xander can propose a new block directly on top of Valerie’s proposal because validators have supplied Will with the QC of Valerie’s block (proof of sufficient support). Xander’s proposal contains the QC of Valerie’s block and a timeout certificate, which summarizes the timeout messages received. Collectively, these prove that Xander followed the protocol during the recovery and did not wrongfully skip Will’s proposal.
Property #2: Leader Fault Isolation
Recall a core property of all pipelined protocols: each leader is responsible for two tasks—collecting votes for the previous block (forming a QC) and proposing their own block. In all prior pipelined protocols, this also meant that each leader was a single point of failure for both of those duties. Let’s illustrate this with the timeline of proposals:
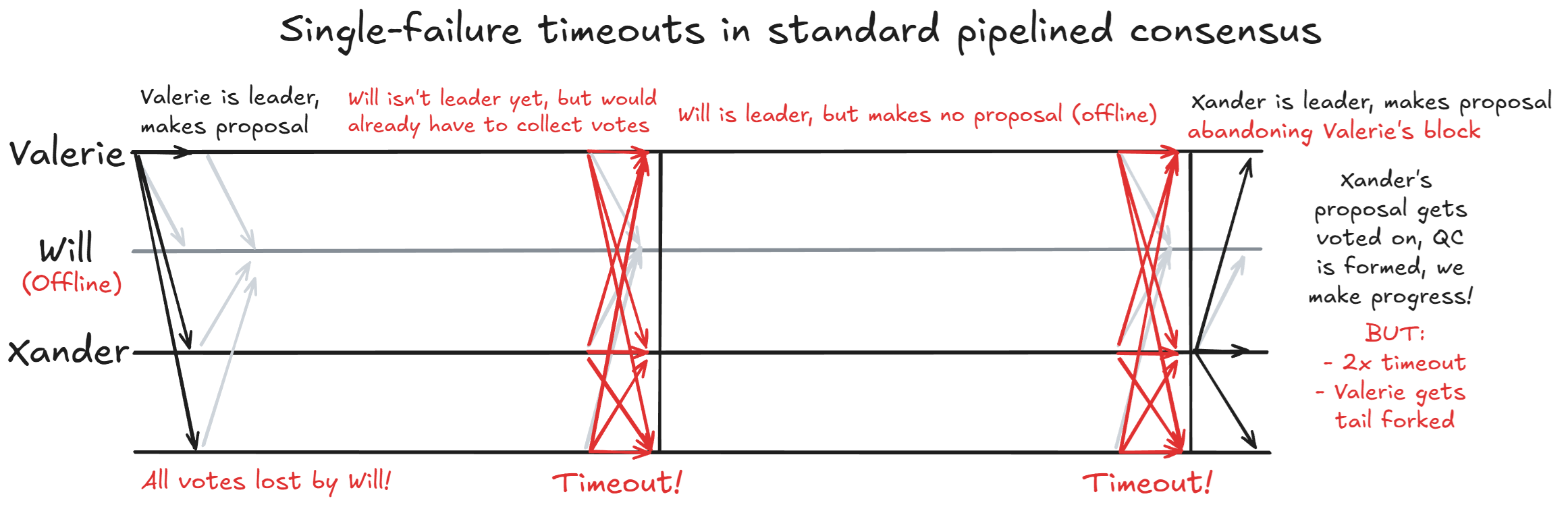
As we can see, a single leader failure means that two rounds time out. Will’s absence causes not only his own round to time out, but also Valerie’s round, as Will is responsible for collecting the votes for her proposal. Timeout periods must be set conservatively to avoid accidentally timing out the round of an honest leader who simply has higher latency due to physical location. If the timeout period was set too aggressively, an honest leader in a more remote location (higher latency) would be at greater risk of timing out their proposal and forfeiting block rewards. This disadvantage produces an incentive to centralize. Consequently, timeout periods are often set conservatively for blockchains that value physical decentralization. In the case of Monad, the timeout duration is 800ms – twice the normal duration of a leader’s round. With two rounds timing out, this means that we could have added four new blocks in the time that it takes us to recover from a single failed leader!
Our updated protocol with its fast recovery fares substantially better. Because Valerie forms and broadcasts a backup QC, her round finishes successfully without timing out. Only Will’s round times out. This is the essence of the leader fault isolation property: a single leader fault only causes a single timeout. Let’s illustrate this again using our example:

What would have been two timeouts (Valerie's and Will's) plus a reproposal round (in the previous MonadBFT protocol) becomes just a single timeout with immediate progress afterwards.
One more chance for fast recovery. Even if the backup QC case fails, the new MonadBFT protocol has one more trick up its sleeve. A validator who sends a tip in a timeout message now includes a vote for that tip. If the recovering leader can gather votes from timeout messages for the same proposal to reach $\ge2f+1$ votes, they can construct the missing QC on the spot and directly extend it with a fresh proposal. Notably, votes cast in the “normal” path can be aggregated with votes in timeout messages, as long as they are cast in the same round. This further strengthens the protocol and increases the feasibility of fast recovery.
The Reproposal Mechanism Remains
The updated MonadBFT protocol handles the common cases efficiently through fast recovery, while the standard recovery path (using reproposals and No Endorsement certificates) ensures tail-forking resistance when there are complex Byzantine failures including malicious leaders or widespread asynchrony in the network.
When is fast recovery infeasible? If a leader is neither fully functional or fully silent, fast recovery may not be possible. For example, if a proposal is received by an insufficient but non-zero number of validators to form a QC, the proposal will be included as a tip in the timeout messages and the standard recovery may be necessary. The same might happen during severe networking disruption between validators. We expect that these cases will be rare instances in practice, meaning that we can benefit from fast recovery most of the time.
The Round History Revolution
Remember this diagram from our previous post? It shows that in traditional pipelined consensus, a single leader failure causes two rounds to fail:

The original MonadBFT's reproposal mechanism preserved honest blocks but consumed a round for each reproposal:

The round preceding the failed leader is marked as “Committed” because that leader made a proposal that was reproposed and eventually committed – but as we discussed, it also incurred a timeout.
Our new, enhanced protocol’s fast recovery gets rid of that extra timeout and the reproposal round following the leader:

Only a single round times out, and in every other round, the leader gets to make a fresh block proposal that gets committed.
What This Means for Monad
With 200 validators providing dedicated service across diverse global infrastructure, occasional leader failures are simply part of distributed systems. Since single offline leaders are by far the most common case, fast recovery ensures these routine events have minimal impact on users.
Concretely, these optimizations cut MonadBFT’s failure recovery time from ~1.6 seconds to just 800ms. For users, this means predictable transaction confirmations; for developers, it means reliable application performance.
The Complete Picture
From the first blog post, MonadBFT achieves the following properties:
✅ Tail-forking resistance through the reproposal requirement
✅ Single-round speculative finality with stronger guarantees on Voted block inclusion
✅ Optimistic responsiveness progressing at network speed
✅ Linear message complexity in the common case
And we now add these features:
✅ Fast recovery following failures
✅ Leader fault isolation bounding Byzantine impact to a single round
For complete technical details and formal proofs, see the new MonadBFT paper. For another high-level summary of the protocol, see Monad’s developer documentation. Our implementation of MonadBFT is open source and on GitHub.
