For an L1 blockchain like Monad, bugs can be catastrophic: there are no chargebacks due to the immutable nature of blockchains, and permissionless participation with significant value at stake creates a highly adversarial environment. In the worst case, bugs can lead to loss of funds; more commonly, they can cause liveness failures. Monad takes security very seriously. This experience report illustrates how we use formal verification to find bugs that frontier models missed in our trials.
Can frontier models find most bugs?
Frontier models have had impressive success in finding bugs in codebases that have been widely tested and reviewed. However, there is little reason to believe that they have found all or even most bugs in those codebases:
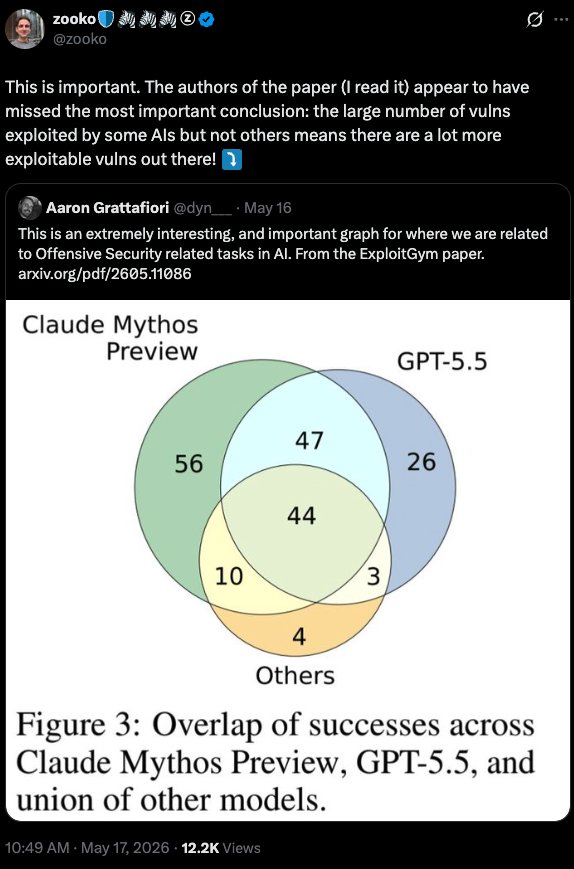
In the thread, zooko explains his argument using an analogy to the capture-recapture method of estimating the number of frogs in a pond:
- Take a sample of size
n1and mark its members. - Release the sample back into the wild.
- Wait a short time, a week perhaps.
- Take another sample of size
n2, counting them2members of the second sample that are found to be marked. N = n1*n2/m2.
Arguments like these should be taken with a grain of salt as the samples (of bugs or frogs) may not be perfectly independent.
Can we find all bugs?
Perfection is impossible, but we can get very close with formal verification, which involves the following for a software system:
- Precisely define correctness for the system. This correctness property should rule out anything that would be considered a bug. Often, it can also rule out certain kinds of inefficiencies.
- Develop a machine-checked mathematical proof that the software system has that property.
Vitalik recently wrote a great intro to formal verification here. He also explains the caveats well. We won't repeat his content. Instead, we share some interesting observations from our experience doing formal verification of critical parts of the Monad blockchain, including the bugs missed by Claude Opus 4.8 (Ultracode effort).
Another advantage of formal verification is that it often leads to simplification and sometimes efficiency gains (e.g. faster, more parallel). In a recent postmortem video after Sui's May 2026 network halt, the Sui team said their formal verification work on the gas mechanism led to simplifications. We will explain how our formal verification efforts identified ways to make Monad faster and/or more user-friendly.
Formal verification @ Category Labs: bugs and inefficiencies found
Our goal is to formally verify the implementation of the Monad blockchain. Toward that goal, we have made significant progress, starting in early 2025. So far, we have verified parts of the implementation that we considered highest-risk, including concurrent features such as optimistic execution and novel Monad features such as reserve balance, which helps parallelize consensus and execution, and optimized page-level storage (MIP-8). Below, we use reserve balance as our main case study. It shows both what formal verification can catch at the design level and what it can miss when an implementation diverges from a proved model. We then explain how we verify C++ implementations and give a shorter second example from MIP-8, where a code-level proof exposed undefined behavior that ordinary Claude review missed. In our trials, several bugs that escaped ordinary review became apparent once the systems were expressed through precise specifications and proof obligations.
Reserve Balance
Monad gets much of its speed from parallelism and pipelining. One important example is asynchronous execution: consensus agrees on the ordering of transactions without waiting to execute them, and execution runs in a separate, slightly lagged pipeline. This gives execution a much larger time budget, but it also means that consensus is validating block n using only an older view of state. In Monad’s docs this lag is described as K blocks, currently 3.
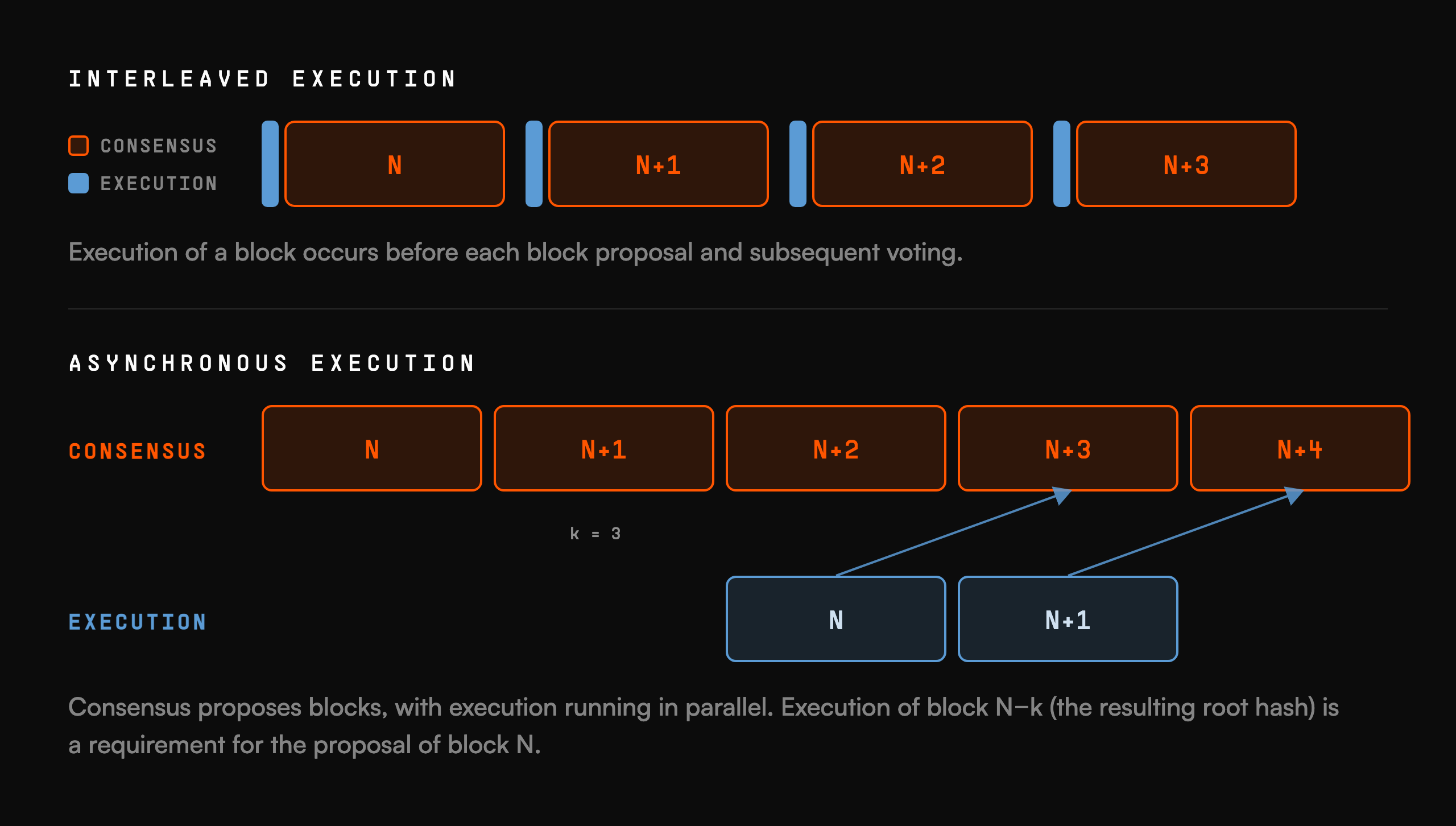
This creates a safety problem. Suppose consensus sees Alice’s balance from K blocks ago and includes a transaction from Alice because that old balance was enough to pay gas. If Alice has already spent her MON in one of the more recent, not-yet-executed blocks, execution may later reach Alice’s transaction and find that she cannot pay the fee. The main complexity in this comes from EIP-7702 delegation, which lets smart contracts run on behalf of EOAs and thus debit them in arbitrarily complex ways. To solve this, we introduce the concept of reserve balance. A balance of 10 MON is reserved just to pay fees. Roughly speaking: except for gas fees, execution prevents net debits from cutting into this reserve; transactions revert otherwise. This allows consensus to safely include transactions whose fees sum to less than the effective reserve, which is the minimum of 10 MON and the balance in the last available fully executed state.
But what if a user wanted to transfer their entire balance to another account? To address this, the design adds a subtle emptying exception, which allows accounts to dip into their reserve balance if the account:
- is undelegated and
- has not recently (within
Kblocks) sent any delegation/undelegation requests.
For a deeper dive on reserve balance, check out the dedicated docs page.
Properties proved
The main correctness property we proved is fee solvency:
Any transaction accepted by consensus must be able to pay at least its gas fees when the transaction gets executed.
The formal Rocq statement can be found here. (Rocq was formerly known as Coq.) The Rocq proof about the model took 4 person-weeks in July 2025. At that time, Codex/Claude agents were in very early stages and much less effective at Rocq proofs, so this proof was done manually. Today, we would not be surprised if Codex/Claude agents did >95% of this proof automatically, thus cutting the time needed from 4 person-weeks to less than 1. The fee solvency property is critical because, as of June 2026, if the sender's balance is found to be insufficient at the beginning of transaction execution, block execution aborts, thus halting the chain. Violation of a similar property recently (May 2026) led to a halt of the Sui chain.
It is important to note that this proof is about a model of the reserve balance checks, not the actual code. Later on, we did prove that the actual C++ function that implements the reserve balance checks is equivalent to the model. Also, there are many other properties worth proving, as we discuss near the end of this Reserve Balance section.
Bugs found
Bug 1: Sender-only balance check
We realized early on that there could be subtle correctness issues in the reserve balance design, so we started formal verification even before implementation started. At that time, all we had was a LaTeX document (for Monad Initial Specification Proposal ) that we wrote to align the community on the design of reserve balance from both consensus and execution clients' points of view. In a few weeks, while modeling and proving the fee solvency property in Rocq, we found the first bug. As mentioned before, roughly speaking, except for gas fees and the emptying exception, execution prevents net debits from cutting into the 10 MON reserve; transactions revert if they attempt to do so. This check is done near the end of transaction execution. In the initial version of the LaTeX document, the execution check was only checking the sender's balance. This is a problem because a transaction sent by Bob may have made a CALL to Alice, an EIP-7702 delegated EOA, which may result in a smart contract executing a CALL to transfer all of Alice's balance to some other account. If the next transaction in the block is by Alice, it would not be able to pay its fees unless there was an intervening credit. But consensus may have already accepted that transaction because it assumes that balances below 10 MON are reserved for fees and it was relying on execution to enforce that. The fix was to check all changed accounts that are not smart contracts.

In hindsight, this was a simple bug, which perhaps would have been found during a careful review or testing. However, surprisingly, in our June 5, 2026 trial, Claude Opus 4.8 (Ultracode effort) did not find the bug when we gave it the version of the LaTeX document we started formalizing in Rocq in July 2025.
In this example, Claude found a different and perhaps more subtle bug. This bug was also found during a manual review of the LaTeX document and later during the Rocq proof. As mentioned before, the reserve balance design has a subtle emptying exception, which allows accounts that are undelegated and have not recently (within K blocks) sent any delegation/undelegation requests to empty their accounts. Initially, the exception criterion was unsoundly more permissive: the execution check allowed undelegated accounts that had not sent recent delegation requests to empty, even if they had sent recent undelegation requests. The linked chat transcript explains why this is a problem and gives a specific counterexample.
Bug 2: Delayed reserve-threshold update
What if a user doesn’t want to set aside 10 MON for fees? We explored a configurable reserve balance, set via a call to a precompile. Because the precompile can be called in arbitrary ways in smart contracts, consensus cannot track this without executing transactions fully. So our design built in a buffer of Kblocks after which the change would be effective. In one of our initial designs written as a LaTeX document, there was a subtle bug: if a user increases their threshold in block n, between blocks n+K andn+2K, consensus incorrectly accepts a transaction that would be unable to pay the gas fee. Even before the implementation of this feature started, the bug was found during formal verification.
Codex almost automatically changed our old formal model to allow such delayed dynamic reconfiguration and reproved fee solvency in Rocq. From the chat log, it looks like it did the proof using the proof-guided design approach championed by Prof. David Gries in his 1981 book The Science of Programming. He advocates that specifications (correctness statements) should be written first and then implementations/designs should be derived from them together with proofs: proofs/specifications should not be an afterthought. After Codex came up with its design and proved its correctness, in the same thread, we asked it to compare the permissiveness of its design with that of the one in the LaTeX document. It correctly judged its own design to be less permissive. But it did not mention that the LaTeX version was too permissive to be sound (had a bug). We then explicitly asked it to try to find a counterexample and it did so on the first attempt. This thread was with Codex GPT-5.2, in January 2026. It was the same thread in which Codex did the proof of its own sound design.
We have also tested newer models on this bug. All experiments used the maximum reasoning effort available at the time.
The table shows an interesting pattern: newer model versions found bugs without Rocq proofs that earlier versions of the same model only found with Rocq proofs. At the same time, newer versions did not find other, sometimes seemingly simpler, bugs in our trials. It is not clear whether earlier Rocq proof artifacts or discussions appeared in the training data of the newer model from the same company. Also, our sample size is too small to support definitive conclusions.
The next two bugs, Bug 3 and the MIP-8 object-boundary bug, had never previously been discussed with Anthropic's models, and Claude Opus 4.8 (Ultracode effort) did not find either in our trials.
Bug 3: Missing optimistic-execution balance assumption
Even when a model of a system is proved correct, the actual implementation can diverge from the model and thus have bugs. This is especially true of a model designed to explain what the system does (the user-visible behavior), rather than the underlying mechanisms. Thus, it is also important to formally verify the actual code. If the actual code is written in a higher-level language, the compiler should ideally be verified. The implementations of the reserve balance checks (consensus, execution) were done after the proof of the model was finished. Yet, there was a bug in the implementation of the execution-side reserve balance check. This bug led to a single testnet node crashing because a transaction was unable to pay the gas fee. Other nodes did not crash as this bug only manifests under some concurrent interleavings of Monad's optimistic execution. The bug was caught and fixed long before the mainnet release.
This bug would have been caught if we had done the Rocq proof that the C++ function implementing reserve balance checks in execution is equivalent to the one in the model that was proved correct in Rocq: the obvious specification, based on the many specifications we had already written by that time, rules out that bug.
We were unable to get Claude Opus 4.8 (Ultracode effort) to find the bug in repeated trials. However, it did find the bug when we gave it the formal Rocq specification of the C++ function and asked it to find a counterexample to the specification: we discuss this in more detail below.
First, we briefly describe the bug. The execution-side reserve balance check needs to read the pre-transaction balance and the final balance of changed accounts and ensure that the latter is not too low with respect to the former, especially if the latter is less than 10 MON. The bug was due to insufficient documentation in another feature that was merged just before the reserve balance implementation. This was the relaxed account-balance validation feature, which changed the semantics of reading balances of accounts in a subtle way that was (in hindsight) not well communicated to the rest of the team. So we briefly describe relaxed account-balance validation next:
Relaxed account-balance validation improves Monad's optimistic parallel execution by avoiding retries for balance conflicts that do not actually matter. In ordinary optimistic execution, a transaction records the state it read while executing speculatively. When the transaction is later merged into the block state, those reads are validated. If a value it read has changed, the transaction is retried. That rule is sound, but too conservative for balances. Many EVM balance operations are relative. For example, suppose transaction T does a lot of expensive work:
SLOADs slots1..100;- computes their sum;
SSTOREs the sum into slot101;- does a
CALLthat transfers1 MONto an undelegated EOA.
During the CALL, execution needs to check that the caller has at least 1 MON. It does not need to know the caller's exact balance. If T speculatively executed when the caller's balance was 100 MON, and an earlier transaction in the block later changes that balance to 99 MON, then the CALL is still valid: 99 MON >= 1 MON. Without relaxed balance validation, the merge step sees that the caller's balance changed from the value T observed and rejects the speculative execution. T must be retried, even though the retry will do the same SLOADs, compute the same sum, and still succeed at the CALL. All the expensive storage work is thrown away for no semantic reason. Relaxed balance validation avoids this. When execution only needs a balance to be above some threshold, it records a lower-bound constraint instead of an exact-balance dependency. In the example above, T records roughly "the caller's pre-transaction balance must be at least 1 MON," not "the caller's pre-transaction balance must be exactly 100 MON." At merge time, if the actual balance still satisfies the lower bound, the transaction can merge without retrying after linearly adjusting the final balances.
The relaxed account-balance validation PR recorded a balance lower-bound assumption at places where execution only cares about the balance being at least a certain value. At other places, like SELFBALANCEor BALANCE, which let the user program read the balance and do arbitrary things with it, it recorded an exact-balance assumption. However, reserve balance was implemented concurrently in a different branch, and it was not updated to properly set the optimistic assumptions when the implementation read the speculated pre-transaction balance. In the relaxed account-balance validation PR, we should haveencapsulated this functionality to make it impossible for callers to use incorrectly, even if the caller code is not formally verified. We did this encapsulation later.
In June 2026, we investigated whether Claude Opus 4.8 (Ultracode effort) would find the bug:
Although a Rocq proof of the Rocq spec would have found the bug, Claude found the bug even before doing the proof, when it was told to review the spec and find counterexamples. This is an important observation because even though Codex/Claude have become great at doing Rocq/Lean proofs, in our experience, they often take days to complete (with minimal supervision). It is much quicker to develop just the specs, and Codex/Claude are great at finding counterexamples to specs. Many times, when asked to do proofs in Rocq, they will spend days trying to prove a property that is not actually true, often running in circles and making no real progress but immediately finding counterexamples when explicitlyasked to do so.
Improvements identified
- Smart contracts at the end of a transaction are allowed to empty. One suboptimality in an initial reserve balance design was that the execution check was too conservative about accounts that became smart contracts during the transaction. The reserve balance mechanism exists to ensure future transaction senders can pay gas. But smart contract accounts are not expected to be transaction senders, under the usual cryptographic assumption that nobody has the private key for a contract address. So if an account is a smart contract in the final state of the transaction, there is no fee-solvency reason to force it to keep a reserve balance. Later, the implementation was updated to match the proved model by using the final-state code hash for reserve balance checks, making the check more liberal and less likely to revert transactions unnecessarily.
- A simpler and more permissive redesign. The proof effort also led to a more ambitious redesign of the reserve balance mechanism. This proposal is much simpler than the current design: it removes the need to maintain the history of the previous
2Ktransactions, allows any currently undelegated sender to empty, and permits multiple emptying transactions as long as consensus’s balance lower-bound estimates are still sufficient. The execution check becomes strictly more liberal, and the Rocq definitions/proofs are less than half the size. The tradeoff is that the consensus-side algorithm changes more substantially: consensus does a shallow execution that tracks, per account, whether the account is delegated, its configured reserve balance, and a lower bound on its balance. We have not adopted this proposal, partly because it is a larger design change we came up with too late, after all the audits in preparation for the mainnet launch. Also, although we have proved the (C++) implementation of the execution-side check, we haven't yet proved the (Rust) implementation of the consensus-side check (more on that below).
Caveats and future work
In our proofs, we assume an abstract model of core EVM execution, because reserve balance is a wrapper that is mostly independent of core execution. We assumed seven properties about core EVM execution, mainly about how transactions can affect balances and delegation statuses. Ideally, we should make a model of Monad execution in Rocq, designed to define what Monad computes rather than how it does so efficiently. Then, these assumptions could actually be proved with respect to the model. We will have more to share on those efforts shortly!
The consensus-side check is implemented in Rust and has not yet been verified. This should not be hard, but we need to figure out the appropriate tooling (e.g. Rust semantics formalized in Rocq) for this.
The fee solvency property we proved is not the only important property we care about. It may be the most important one. There are other useful properties, e.g. that the mechanism is as user-friendly as possible. User-friendliness is hard to formally define, but we can consider a few concrete dimensions. For example, an internal review found that execution was reverting some transactions unnecessarily. In hindsight, this user-unfriendliness would have been avoided if we had proved the following minimal reverts property: the execution check should revert a transaction only if there is a possible future transaction that consensus can accept and would not be able to pay its gas fee during execution.
There was another way the design was user-unfriendly for some use cases. If Alice CALLs Bob (untrusted), and Bob is delegated, Bob could violate his own reserve balance condition by debiting his account too much and thus cause the whole transaction, including Alice's work, to revert. When CALLing Bob, Alice has no way to prevent Bob from causing the whole transaction to revert. This was later addressed with MIP-4, a precompile that can be called to determine whether the execution's reserve balance criteria have already been violated.
In hindsight, this user-unfriendliness would have been avoided if we had proved a general safe-call non-interference property. Suppose a transaction’s top-level control reaches Alice, where Alice may be either a smart contract account or a delegated EOA. When Alice calls an untrusted account Bob, Alice should have an implementable safe-call discipline that prevents Bob from affecting Alice except through the explicit result of the call discipline: success or failure, return data, gas effect, any net MON credited to Alice, and the result of post-call safety checks defined by the discipline. Formally, conditioned on those results, at the end of the transaction, Alice’s final non-balance account state should be completely independent of what Bob does. Alice’s balance decreases by at most the value explicitly transferred in the CALL. The right way to define this discipline seems hard without formal proofs. Reentrancy attacks are a historical example of this kind of interference. In the DAO attack, untrusted callee code recursively re-entered the DAO’s split function before the outer call completed, collecting Ether multiple times in one transaction.
Next, we describe a bug we found while formally verifying C++ code. Again, this was missed by Claude Opus 4.8 (Ultracode effort) in our trials.
How we formally verify C++ code
For proofs of C++ programs, we use SkyLabsAI's BRiCk framework. It represents C++ programs as abstract syntax trees in Rocq and gives those trees a weakest-precondition semantics in Iris separation logic. Its cpp2v tool visits Clang's AST and converts it in a dumb, straightforward way into the same (modulo syntax) tree in Rocq. This simplicity is important because we have to trust this translation. For example, it does not try to convert C++ to a functional program in Rocq, which can be much more complex and thus harder to trust for correctness. In addition, BRiCk gives a weakest-precondition semantics to every kind of C++ AST node. In separation logic, this defines the pre/postcondition of every primitive AST node in C++, e.g. the assignment operator, branching constructs (switch/if-then-else), loop constructs, and function calls. A C++ proof of a complex program can then be derived by just composing those rules for all the nodes in the program's AST. BRiCk provides algorithmic (deterministic and non-neural) automation to do most of this reasoning. The user still has to provide certain creative insights, such as loop and concurrency invariants: parts that are impossible to algorithmically automate in general. However, these parts can often be provided by LLMs in agentic workflows, and Codex/Claude have become quite good at doing that. Here is a demo of how the BRiCk automation works. It is the first video of a three-part lecture series demonstrating how to prove concurrent C++ programs in Rocq.
MIP-8: a C++ object-boundary bug
Monad Improvement Proposal (MIP) 8 is primarily a user-facing improvement in gas fees: if a contract has already paid to load one storage slot, then nearby slots should be cheaper to access. To support this, MIP-8 changes the storage commitment so it commits to pages rather than individual slots.
This section focuses on the bug we found while proving the C++ implementation equivalent to the model we already proved correct. A separate technical appendix describes the full MIP-8 theorem, the proof effort, the performance improvement suggested by the proof, and the remaining compiler caveat.
The C++ proof found C++ undefined behavior (UB) in an earlier page_commit implementation. page_commit hashes each active pair of storage slots as one 64-byte BLAKE3 input. Each slot is a bytes32_t struct, derived from evmc_bytes32, which just contains an array of 32 bytes. The old implementation expected the hash function to read the second slot from the base pointer to the 32-byte array of the first slot. The definition of bytes32_t guarantees that bytes of consecutive slots in this arraywill be laid out adjacently in memory. Nevertheless, according to the C++ standard, pointers are abstract concepts and a pointer obtained by indexing into one array cannot be safely used to access the contents of an adjacent array, without notifying the compiler, e.g. with a reinterpret_cast. Below, we will see a simpler example with a similar UB, where the compiler produces incorrect code by exploiting the UB.
The fix was to first use reinterpret_cast into a raw byte array.
In our trial, Claude Opus 4.8 (Ultracode effort) did not find this bug when we asked it to review the C++ file (before the fix) for undefined behavior and BLAKE3 buffer issues, even though we gave a hint by explicitly asking it to find C++ UB issues. It did not find any UB issue in the page_commit function or its call chain. It did find a bug in an unrelated function that was not proved.
The following smaller example has a similar adjacent-array UB.
#include <cstdlib>
#include <cstdio>
struct Slot { int words[8]; }; // 32 bytes
struct Page { Slot slots[2]; };
__attribute__((noinline)) int bad(Page *p, int n) {
p->slots[1].words[0] = 123;
for (int i = 0; i <= n; ++i) {
p->slots[0].words[i] = 0;
}
return p->slots[1].words[0];
}
int main(int argc, char **argv) {
Page p{};
int n = argc > 1 ? std::atoi(argv[1]) : 8;
int r = bad(&p, n);
std::printf("returned=%d actual=%d\n", r, p.slots[1].words[0]);
}In our experiment, compiling this with GCC 15 on x86_64 Linux and -O3 -Wall -Wextra -Warray-bounds=2 -Waggressive-loop-optimizations produced no warnings. Running the optimized binary with argument 8 printed:
returned=123 actual=0That is wrong for the byte-level operation the programmer intended: the loop did overwrite the first word of slots[1] in memory, so actual is 0, but bad returned the old value 123. The issue is the iteration i == 8. The programmer intended that write to step from the eight words of slots[0] into the first word of the adjacent slots[1]. But the expression p->slots[0].words[i] indexes past the end of the words array inside slots[0], which is undefined behavior in C++. This is not a compiler bug: once the program has UB, C++ imposes no requirement on the generated program. GCC can assume that a defined access through slots[0].words[i] cannot reach slots[1], so it keeps the earlier 123value instead of reloading after the write. For the same reason, page_commit needed to first derive a pointer from the enclosing slots array as raw bytes, rather than from the 32-byte array inside the first slot.
Formal verification roadmap
We started formal verification in early 2025, when there were no Codex/Claude agents and LLMs were much worse than today at doing Rocq/Lean proofs. So we focused on parts of the Monad execution client that we thought had the highest risk of bugs. Recently, partly due to the skills and hooks we wrote, and partly due to the advances in LLMs and their CLI agentic harnesses, our Codex CLI setup for doing Rocq proofs of even actual C++ code has become so good that we now aim to formally verify the entire Monad execution client. Toward that goal, below are some substantial formal verification tasks that we plan to look at soon:
- Core optimistic execution: A previous version of
execute_block, which executes a block with parallelization, was formally verified down to the specifications of the callees that execute individual transactions. The proof shows that althoughexecute_blockexecutes transactions in parallel, the result is equivalent to running them sequentially. The specs and proofs were covered as examples in the above-mentioned lecture series. For this proof, we simplified the code by replacing shared pointers with raw pointers and dynamic allocation with static allocation. The proof does not account for the code changes since February 2025. We are working on porting these proofs to the actual latest code, without any earlier simplifications. - EVM-to-x86 compiler: The Monad client uses both an interpreter and a compiler to run smart contracts. Contracts that are called frequently are compiled to x86 and cached. We would prove that the compiled code produces the same result as the Monad reference spec, which is currently in OCaml and will be translated to Rocq.
- TrieDB: We already wrote specs of the TrieDB to prove optimistic execution against it. These specs use expressive notions of ownership splitting in the Iris separation logic to allow clients to call the DB concurrently. We plan to prove that the DB implementation actually satisfies the specs.
- Consensus process: Monad's consensus has complex optimizations for speed and censorship resistance. We plan to prove its safety and liveness. We first plan to prove safety and liveness of a model of Monad's consensus, just like we did for reserve balance. Then we plan to prove that the code is equivalent to it. As a warmup towards this task, we have already proved safety and liveness of a fairly realistic model of the Streamlet BFT consensus protocol, which is simpler.
If any of these projects excite you and you have experience in formal verification, especially in using agentic workflows to accelerate proof/spec development, you should consider joining us.
Lessons
- Formulate correctness statements for the agent to (dis)prove. Frontier models are useful code reviewers, but they often miss bugs, especially those that involve complex non-local reasoning about different parts of a large system, or semantic subtleties.
- A formal spec lets us ask a sharper question:
Here is the property we want. Try to find a counterexample. If you are unable, try to prove the property
- In our experience, this often works better than asking a model to “review the code,” and sometimes even better than immediately asking it to prove the theorem. If the theorem is false, an agent may spend days trying to prove it. But when explicitly asked for counterexamples, it often finds a bug. Our current workflow is: write the formal correctness theorem statements (specs), ask for counterexamples, fix the design, ask again, and only then try to prove it.
- Proving the actual implementation is important. A proof about a model is not a proof about the deployed implementation. By design, models often don't account for implementation details, some of which may be very complex, e.g. due to concurrency that is ultimately linearizable (equivalent to sequential execution).
- Formal verification can also uncover UX and performance improvements. Formal verification is not only useful for safety. A good theorem statement can also capture some guarantees about user experience and performance optimality. Also, proofs can uncover which slower or user-unfriendly parts are not essential.
- Formal verification has become accessible to non-proof specialists. Historically, formal verification required deep proof-engineering expertise. LLMs are changing that. They are now good enough at Rocq/Lean proof work that the human bottleneck is increasingly not writing every proof by hand, but understanding whether the theorem statement says the right thing. For many engineers, the practical goal should be:
Learn enough Rocq or Lean to judge formal correctness statements.
There are excellent tutorials to teach this skill without assuming any background. Suggested reading order:
- Software Foundations, Volume 1, Logical Foundations. You can skim or skip the proof sections.
- Formal verification of concurrent C++ programs in Rocq
